The internet is broken. This is particularly problematic when we live in a world where so much is enabled, facilitated, and disabled by “the internet.” Hell, even defining “the internet” is a rough task. What is it? The line that goes into your house. The stuff you scroll through the data connection on your phone. The stuff you stream, search, and updated. It is the place where you get rich information and useless content.
I’ve owned at managed this domain for decades, but you wouldn’t know it by looking at the archive of content. It only goes back a few months. Between the conception of the dtpennington moniker and now, the domain has pointed and directed to all manner of services, servers, and web products. It was a professional portfolio, a blog, a Tumblr, and lord knows what else. Out there (points to the void that is ‘the internet’) is a graveyard of skeletons of content that I have produced but since lost access to because of so many reasons: dead accounts, corrupted logins, transferred ownerships, etc. It was only in the last year that I decided I needed to settle things down and reduce the tech I rely on to a handful of platforms.
As I type this, there are 45 tabs open in my browser. I’ve been down a rabbit hole this morning that spans across three major, but related, concepts:
- The AI Ouroboros
- Link Rot
- The Dead Internet Theory
The AI Ouroboros.
The large language models of AI that most of us engage with (ChatGPT, MetaAI, Siri, etc) are trained from vast pools of information online. On the surface this meant you could punch in a request and get a full-out essay in just a few moments. It was a fancy search engine.
It is a problem in classrooms. Just about every student is using ChatGPT for their classwork. (archive link)
The problem will compound and, I think, eventually resolve itself as the pools of data these AI bots were trained on have grown into oceans of content – it is learning off the stuff it created (archive link). Eating its own tail so to speak. Without some kind of intervention from Authentic Intelligence, Artificial Intelligence will be increasingly useless.

Which is for the best.
Link Rot
I’m sure there are numerous tweets, status updates, and other results out there that point to something on this domain that no longer exists. On the scale of “me,” I’m sure this is fine enough. I have “updating my 404 page into a defacto landing page” on my grand “todo” list. If you get to the top-level URL, you may as well stick around.
On the grandest of scale, about 25% of the pages that existed at some time between 2013 and 2023 no longer exist. Couple this with the stat that 38% of pages that existed in 2013 are gone, as are 8% of pages that existed in 2023 (just last year!). The result is link rot. It’s a problem. The internet is literally decaying. A quarter of news pages contain at least one broken link, and half of all Wikipedia pages have a broken outbound link in the reference page. (source)
This is the negative consequence of the two theoretical models of the internet. The first, which is largely what we’re looking at now: a decentralized system with each “hub” of information the responsibility of a separate entity. I am responsible for what happens on this domain. Now, multiply that by anyone who has ever said “I’m going to start a blog” and then let the hosting lapse. Or the projects that went to dust because the creator went on to full time work or caretaking. Or, frankly, the sole owners who have died.
Which leaves a whole mess of worms – what happens to your internet when you die?
Link rot is about to get a lot worse as Google is not only ceasing operation of their URL shortening tool, but flat-out breaking every link within it. I can’t even imagine how many links this could impact – Google advises everyone use a 302 redirect. It is kind of a dick move.
This is a problem that spans much further than “oh no, a busted link!” that results in a 404 or 403 error in place of the thing you were hoping to find. Very legit things depend on a link continuing to link. Court documents tied to criminal investigations rely on links to bring up relevant information. Academic papers rely on it. I can’t tell you how many books I’ve read reference a URL, only to have that URL go to a defunct blogspot page.
The reference means “I’m not just making this up, this is a real thing.”
The second model: centralizing everything. As the Library of Congress set out to catalog every book and newspaper in publication, having a centralized repository of pages as they exist wouldn’t be a bad thing. Currently, the Wayback Machine crawls pages and screenshots them – but the pages are few and far between, and the interface is criminally slow. The Internet Archive attempts to catalog source material – images, sounds, publications – in a fully searchable format. To their credit, there is a ton of information. But it relies on users to update the metadata information when they upload, and that is lacking and unstandardized. A central repository is expensive to maintain, and the moment you have it housed by a private entity, you lose control over what happens to the information. Plus, ads. Good lord there would be so many stupid ads.
Link rot (or, I guess, linkrot) as a concern goes back to the mid-90s. By 1998 Jakob Nielsen was concerned over the 6% defunct rate of the links. His solution? Keep your yard clean. If you link to something, link to something good. If you are the kind of place that gets linked to, keep your links up to date. Use a link validator (which are annoyingly expensive nowadays). Unfortunately for Jakob, this is a weighty task for the unpaid.
For this page moving forward, I am using the Archive.PH browser plugin that automatically creates a cached version of whatever I’m linking to. Both links will remain. Who knows what this will all look like a year from now. (you can also add “archive.ph/” in front of any domain and it will search to see if the page is previously saved AND the versions of the page Archive has collected).
The Dead Internet Theory
Where is the line between “theory” and “conspiracy.” The Dead Internet Theory straddles that line. Reading about it has me recalling the viral Abbie Richard’s conspiracy spectrum chart (which is now also available as an interactive tool!)
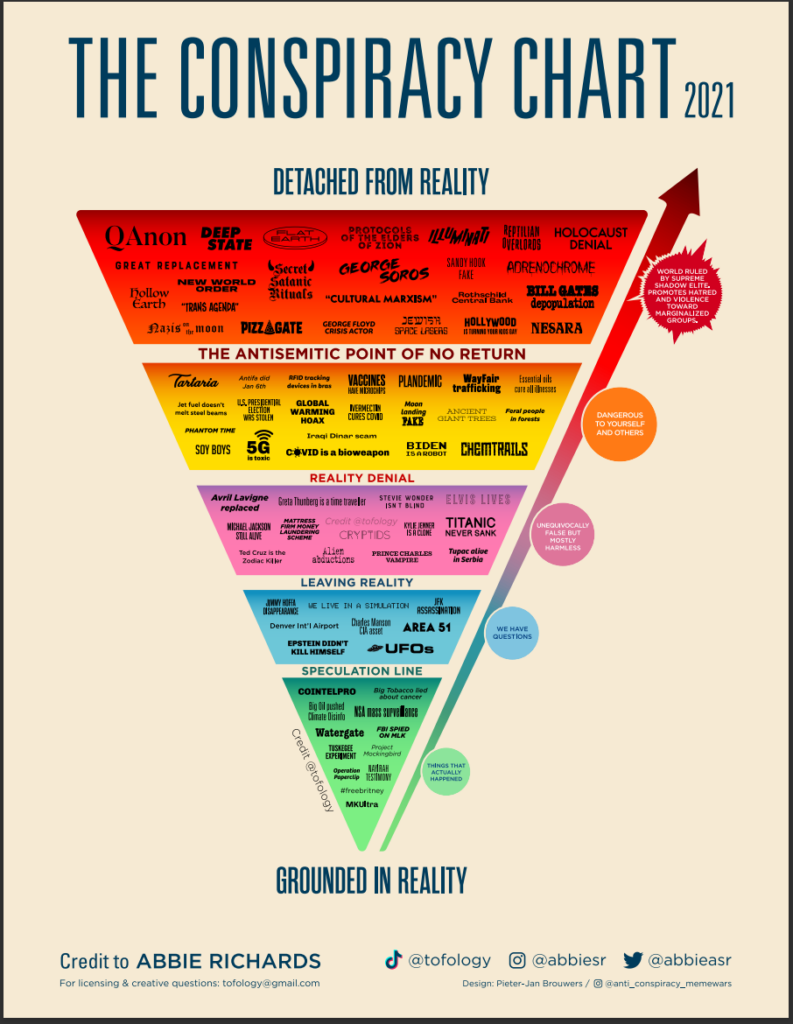
In the most basic terms, dead internet is the idea that there aren’t any humans left. This thing we know as the internet, a human creation for human connection, is so overrun with bots and algorithmically produced content, nothing matters anymore.
The internet you loved is gone. Now it’s all spam. It is AI generated content filling the space left behind with link rot. Fake pictures, deepfake video, AI produced music on Spotify. Eventually it will be bots talking to bots. At one point in my copywriting career I found myself writing copy to respond to voice-enabled search engines. No longer was I trying to convince humans to put items in a shopping cart – no, I needed to appeal to your digital assistant and robots don’t “read” the same way as humans.
Consider this demonstration of an AI bot making a restaurant reservation on behalf of a human with a real human. At this rate, you’ll never get an operator on the phone for customer service again.
The AI and the bots are one thing, the algorithm is another. If you want your content to perform well, you have to do what the algorithm tells you to do. Shorter, dumber content with certain colors, trending sounds, whatever. The creator complies, the audience consumes. We didn’t ask for this kind of world, but here we are.
AI SLOP
We all saw it coming – machines making content for other machines. Images and videos and essays prompted with “and create it in a style that the (X) algorithm will prefer and promote.” The result is something that doesn’t really belong anywhere, but here it is on your feed!
A Way Forward?
I didn’t want to start this website as a blog. The goal isn’t to write for an audience so much as I wanted a space where I could write for myself. A digital garden, an unending research project, a place where I build in public.
As Kenin Zhu puts it: Build a world, not an audience.

It looks like a blog and sounds like a blog, but this is not a duck. This is an experiment.
And because I truly enjoy a manifesto for action, here’s what I’m thinking for this website moving forward:
This is for me. I’ll post when I want but challenge myself to post something new or update something that already exists.
- Enrich every idea. Connect between pages.
- This isn’t about me, it is about the ideas that drag me from one end off the attention sphere to another.
- Link to quality stuff. Go upstream, find the source.
- Make the stuff you want to see but can’t find.
- Less scrolling, more searching.
This entry is long, but it is far from done.